How I do error handling in my REST APIs
As I make more and more REST APIs, I find the need to bubble up an object that will translate to an Http 200 OK result or an RFC 7807 …
ReadMy shared experiences and advice in software
As I make more and more REST APIs, I find the need to bubble up an object that will translate to an Http 200 OK result or an RFC 7807 …
Read
This post details how I fixed an issue in Visual Studio 2019 where variable name suggestions were completely wrong. It may help you, and it may not. Anyways here goes …
Read
This is a reminder to myself more than anything else. It is not often that I get to greenfield a new project. Most of the time, the solution already exists, …
Read
This is another blog post in the series of “Things that gave me plenty of grief, but eventually got solved”. I was working on a component that utilizes the Azure …
Read
Up to this point, I’ve done a number of workshops with partners around the world on the Microsoft Bot Framework and time and again, it is the authentication that always, without exception, …
Read
In a recent partner hackfest, the need to store a Username/Password combination in Azure Key Vault arose. Setting up Key Vault instance was dead easy: Sign in to the Azure portal …
Read
TL;DR In this blog post, I talk about how I spend 3 hours setting up a chat bot that can recognize batteries using the Microsoft Custom Vision API. Recently, a …
Read
What is Application Insights Anyway? Application Insights is an extensible Application Performance Management (APM) service for web developers on multiple platforms. Use it to monitor your live web application. It …
Read
If you haven’t yet heard about the ESP8266 then it’s time for you to wake up and get serious! This little beauty is a seriously low-cost WiFi chip with a …
Read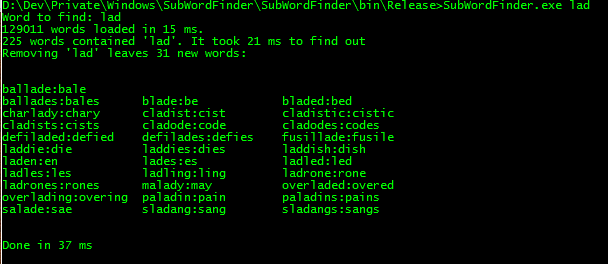
In this post, I explain how I made the program “SubWordsFinder” that takes a string, and finds all real English words that contain that string, then removes the string from …
Read